LLM技能从提示词压进权重
值得看指数 70.0 NO. 019 · 2026.06.10
upvotes49comments3
为什么值得看
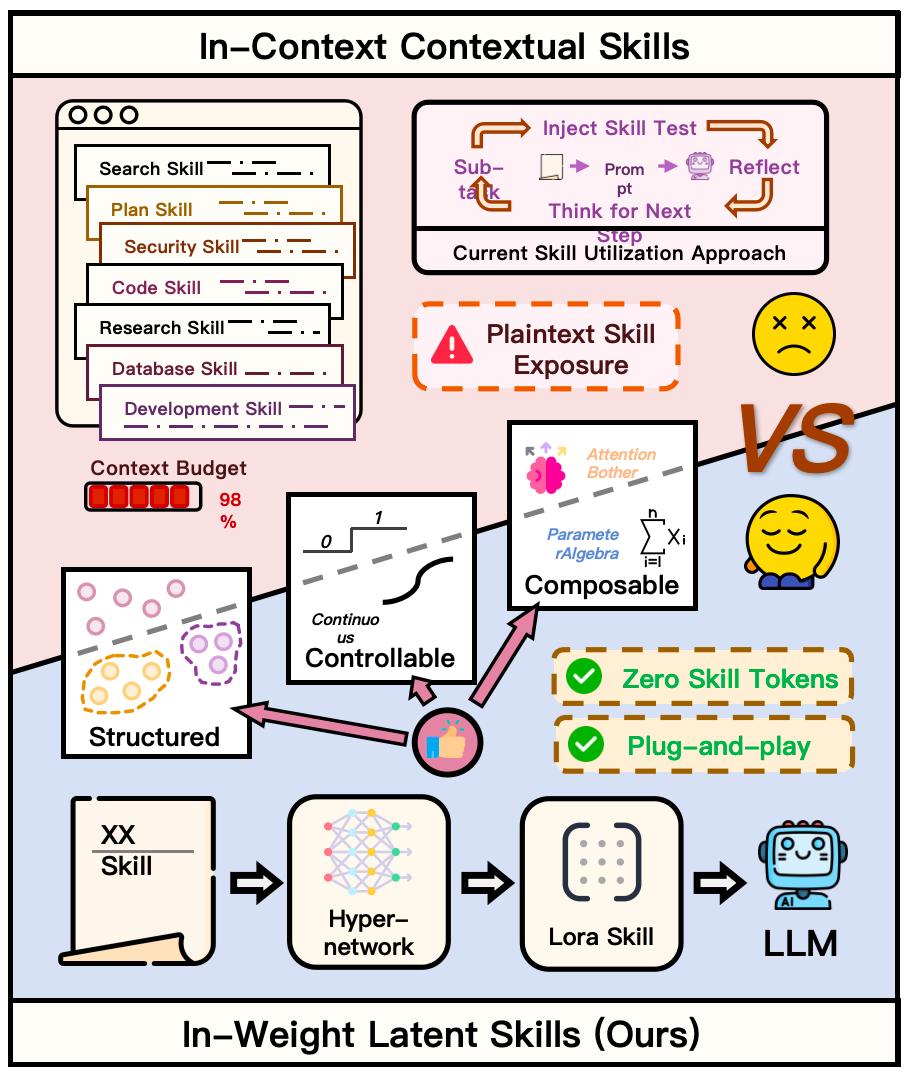
LatentSkill提出将Agent的文本技能描述压缩为模型权重中的隐向量,摆脱长上下文依赖。对构建复杂Agent系统的工程师来说,这意味着技能库可无限扩展而不受窗口限制,且调用延迟更低。
媒体预览
编辑判断
当前主流Agent框架如AutoGPT、LangChain依赖长上下文堆砌工具描述,上下文一爆就翻车。这篇的核心操作是把文本技能蒸馏成低秩权重扰动,类似LoRA但针对技能语义空间,理论上可叠加数百个技能而不占token。
论文提到在ToolBench上技能检索准确率提升23%,但没给具体模型尺寸和训练成本,落地性存疑。更现实的用法可能是和现有RAG管线结合:用向量库召回技能描述,再用LatentSkill压缩高频技能进权重,减少每次调用的检索开销。
代码和训练脚本尚未开源,建议先mark住,等放出来跑通ToolBench复现再决定是否投入生产。