从零手搓完整LLM训练管线
推荐指数 73.0 NO. 003 · 2026.06.11
Stars5,151
为什么值得看
纯PyTorch手写Transformer预训练+后训练全链路(SFT、RM、PPO、DPO、GRPO),支持单GPU训Billion参数模型,基于真实数据集实现。作者正在找AI PhD岗位。
A straightforward method for training your LLM, from downloading data to generating text.
媒体预览
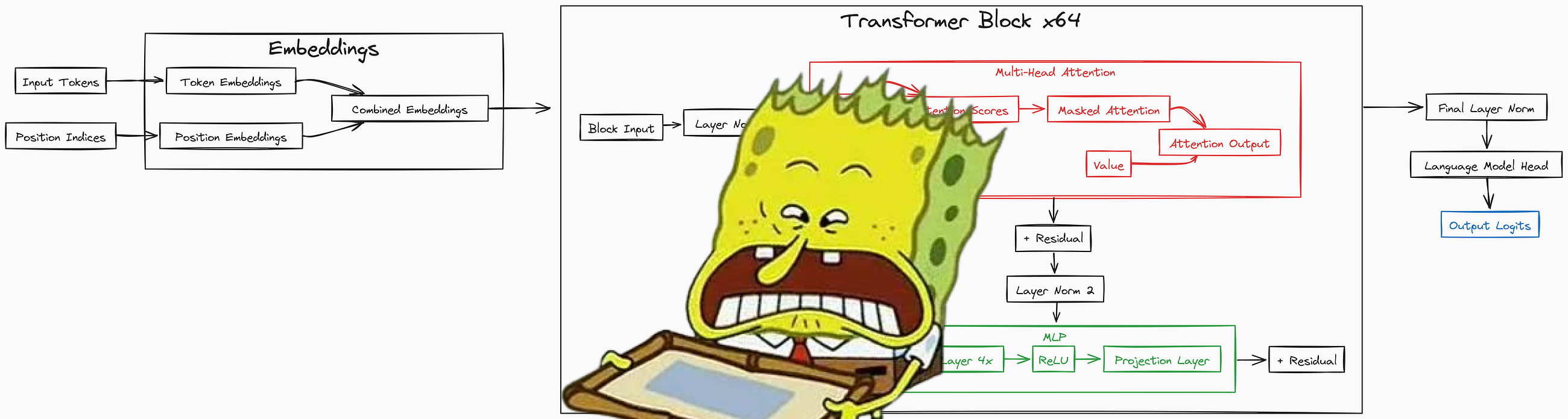
编辑判断
这个repo的稀缺性在于'全链路手写'而非调用HuggingFace或TRL。目前社区里nanotron做预训练、trl做RLHF是主流分工,但想理解底层原理的人往往需要啃多个代码库。FareedKhan把预训练到GRPO/RLVR全部串在了一个repo里,且用DDP+bf16做了多GPU适配,降低了从'读懂论文'到'跑通实验'的门槛。
对两类人价值最大:一是面试前需要快速重建LLM训练直觉的候选人,比读minGPT或nanoGPT更贴近工业界后训练流程;二是想做垂直领域小模型(如法律/医疗推理模型)但不想被Transformers库封装层绑架的团队,可以以此为基线做二次开发。5151 stars说明这个需求确实存在,但代码生产力和长期维护性待观察。
Star History

生态分析
Experimental
面向学习者和研究者的轻量级LLM全栈训练教程与工具包
独特价值:纯PyTorch手写实现,单GPU可训B级模型,覆盖RLHF全算法
竞品: