OpenAI 开源通用语音识别模型
推荐指数 60.0 NO. 007 · 2026.06.07
Stars101,790
为什么值得看
Whisper 是 OpenAI 开源的 Transformer 序列到序列语音模型,支持多语言识别、语音翻译和语言检测,用单一模型替代传统语音处理的多阶段流水线。10万+ star 说明它已成为语音 AI 的事实标准基座,做语音应用的团队可直接接入省去自研成本。
Robust Speech Recognition via Large-Scale Weak Supervision
媒体预览
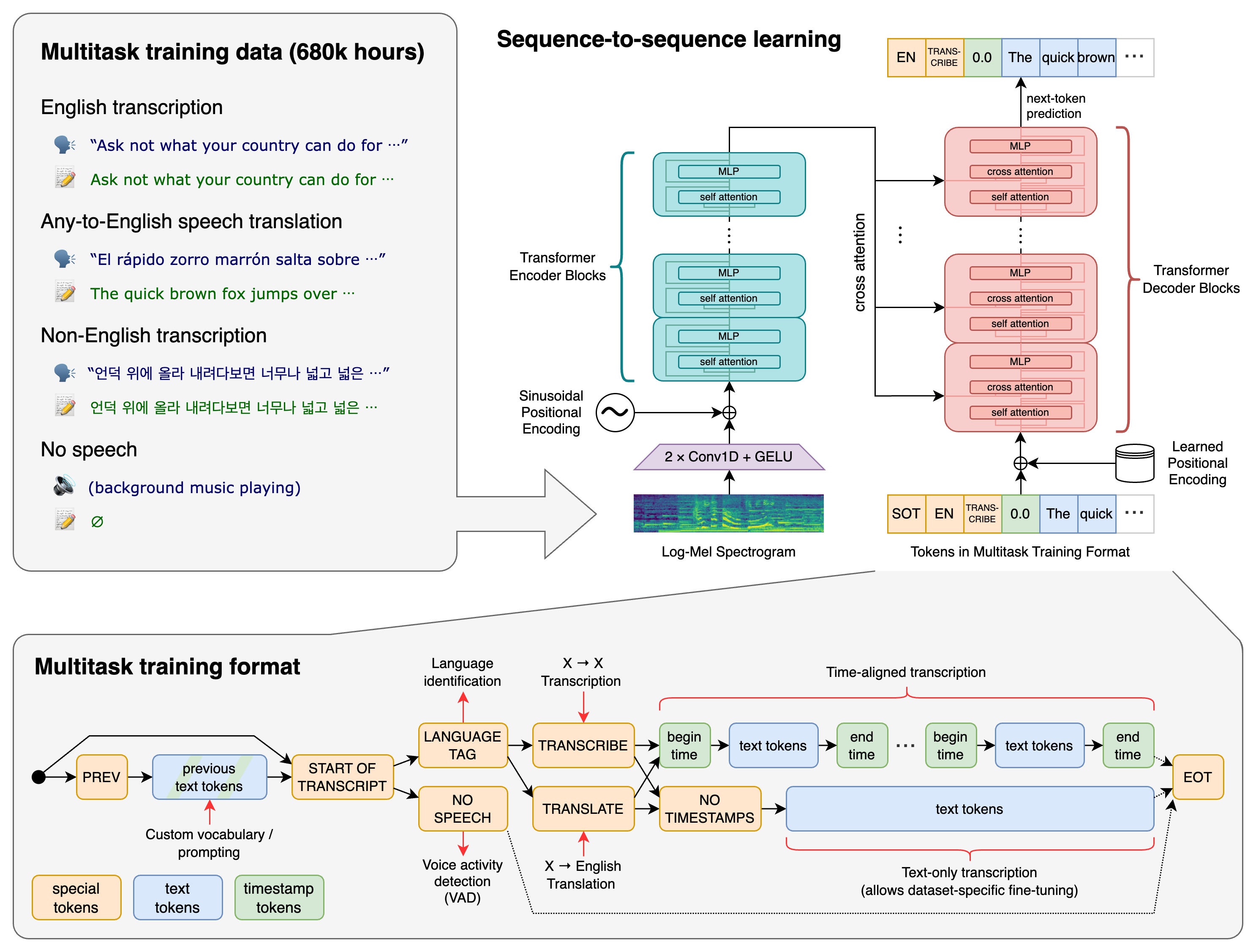
编辑判断
语音团队之前做多语言识别通常要拼接 Kaldi 或 Wav2Vec 2.0 再加单独的翻译模块,管线复杂且语种覆盖有限。Whisper 的 trick 是把所有子任务统一成 token 预测,靠 special tokens 做任务路由,一个模型端到端搞定。
跟 Wav2Vec 2.0 相比,Whisper 对低资源语种的泛化明显更好,且不需要额外的语言模型解码;缺点是实时性一般,16k 音频 base 模型也要 1-2x 实时率。
如果你在做播客转写、会议记录、视频字幕这类离线批处理场景,Whisper 几乎是零思考成本的选择;但要做实时语音交互,建议看看 faster-whisper 或 distil-whisper 这些衍生优化方案。
Star History

生态分析
Production
语音 AI 领域事实标准基座模型,定义端到端语音识别新范式
独特价值:单一模型覆盖多语言识别翻译检测,零样本开箱即用降低接入门槛
竞品:
google/w2v-bert Google 自研语音预训练模型,未开源完整推理框架
facebookresearch/wav2vec 2.0 Meta 语音表征学习,需下游微调无端到端能力
NVIDIA/NeMo NVIDIA 全栈语音工具包,配置复杂非单一模型
espnet/espnet 学术语音工具包,模块化设计非即插即用
snakers4/silero-models 轻量语音模型,精度与多语言能力不及 Whisper