Perplexity 把搜索重写成代码生成
推荐指数 61.0 NO. 013 · 2026.06.03
发布2026/06/02Score54Comments16
为什么值得看
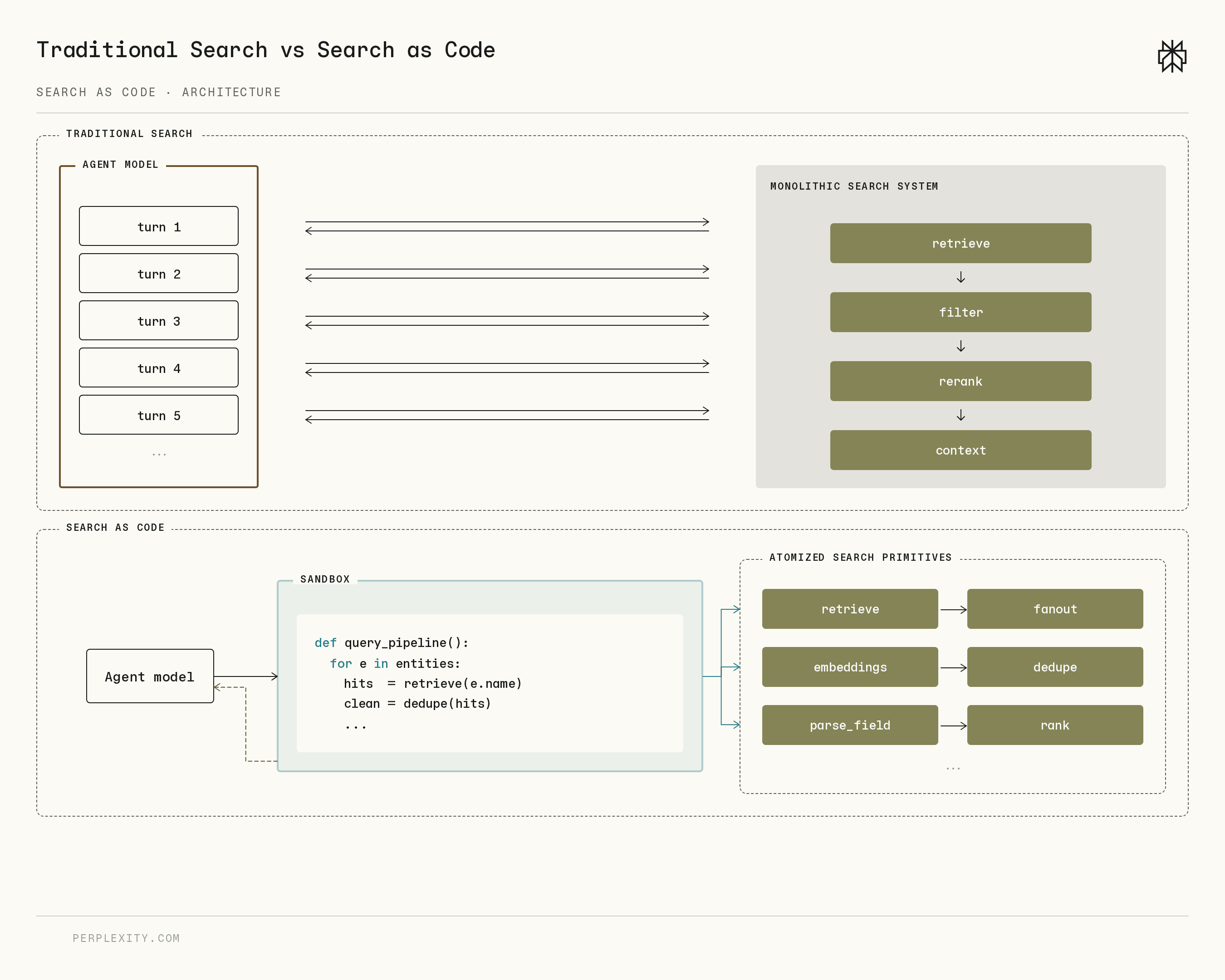
Perplexity 提出将传统搜索管道替换为代码生成范式,让 AI Agent 通过生成可执行代码来动态调用搜索工具、处理多步任务。这意味着搜索从"返回链接列表"进化为"按需编排检索逻辑",更适合复杂 Agent 工作流。
媒体预览
编辑判断
传统搜索管线(query -> retrieve -> rerank -> generate)的假设是用户想要一个答案,但 Agent 的任务往往是开放式的——可能需要先查天气、再搜航班、再比价。Perplexity 这个思路本质是把搜索的"控制流"也交给模型生成,类似 ReAct 的进化版,但把动作空间从自然语言推理变成了结构化代码。
这和 LangChain 的 LCEL 或 LlamaIndex 的 query pipeline 有重叠,但 Perplexity 更激进:不是预设 DAG,而是每次让模型从零写检索脚本。好处是灵活性极高,坏处是延迟和可靠性更难控。如果你在做垂直 Agent(法律、医疗、金融研究),现有框架的固定检索链路往往是瓶颈,这个方向值得跟踪,但建议等开源实现出来再评估生产可用性。
社区反馈
意见分歧 16 条评论
核心争论:代码生成搜索是否优于现有迭代搜索和子Agent方案
[flagged]
Can you please not post AI-generated or AI-edited comments to HN? It's not allowed here - see https://news.ycombinator.com/newsguidelines.html#generated and https://news.ycombinator.com/item?id=47340079. Of course, it's impossible to know for sure what was LLM processed
I found this approach very interesting and was wondering if it could be applied to grep-based search for coding agents to increase speed and reduce LLM turns, but the part im not quite understanding is how the model will know enough about the codebase to construct a complicated multi-stage search pi