华为开源 vLLM KV 缓存量化后端
推荐指数 79.0 NO. 013 · 2026.06.05
发布2026/06/04Score86Comments7
为什么值得看
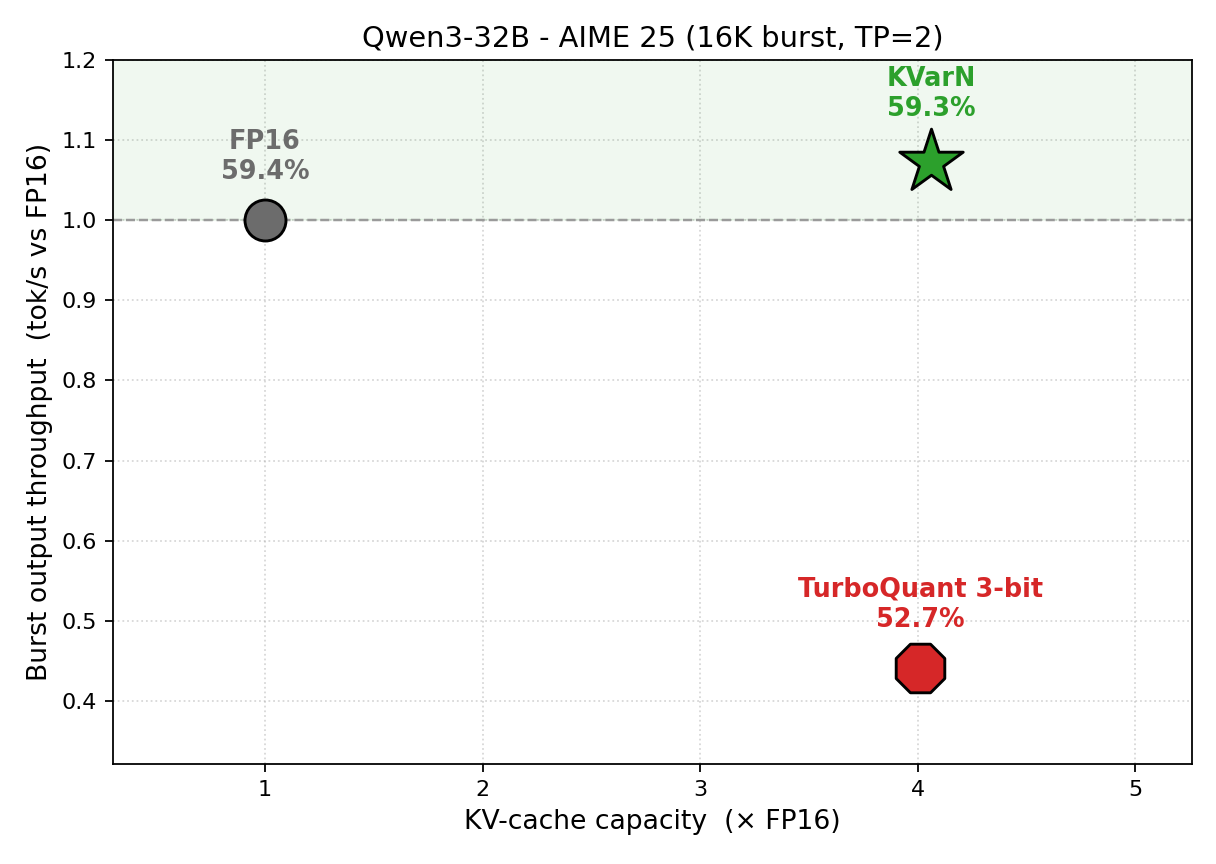
KVarN 是华为推出的原生 vLLM KV-cache 量化后端,无需校准即可实现 3-5 倍上下文扩展,吞吐量超 FP16 且精度无损。对部署长上下文 Agent 和推理服务的团队,这是降低显存瓶颈的即插即用方案。
媒体预览
编辑判断
KV-cache 显存瓶颈是长上下文推理的公认痛点,业界主流做法是用 FP8 或 AWQ 做权重量化,但对 KV-cache 本身的量化支持一直碎片化,KCache、StreamingLLM 等方案要么需要改模型结构,要么精度损失明显。
KVarN 的关键差异是原生集成 vLLM 且 calibration-free,意味着现有服务加一行 flag 就能跑,不需要准备校准数据集——这对已经有 vLLM 推理管线的团队迁移成本极低。
如果你在用 vLLM 跑 32K+ 上下文的 Agent 或 RAG 服务,显存吃紧又不想动模型权重,这个值得优先试用,注意关注其在多轮对话场景下的实际精度衰减。
社区反馈
意见分歧 7 条评论
核心争论:技术价值获认可,但开源策略受质疑:为何不直接给 vLLM 提 PR
Why this is not a PR for vLLM ?
It's the output of a research paper; the authors are not trying to build up vLLM, and they probably have no incentive to do so. You can submit a PR, though! It's easier now while the divergence is low, so don't wait. Since there are six authors, I bet you could get help with the inevitable review ch
And with the help of AI, pointing at AI at this paper and saying "making a vLLM PR from this paper" tends to work surprisingly well, even if you need to nudge it a little bit along the way.