统一评测协议暴露编码Agent短板
推荐指数 67.0 NO. 024 · 2026.06.12
upvotes55comments1
为什么值得看
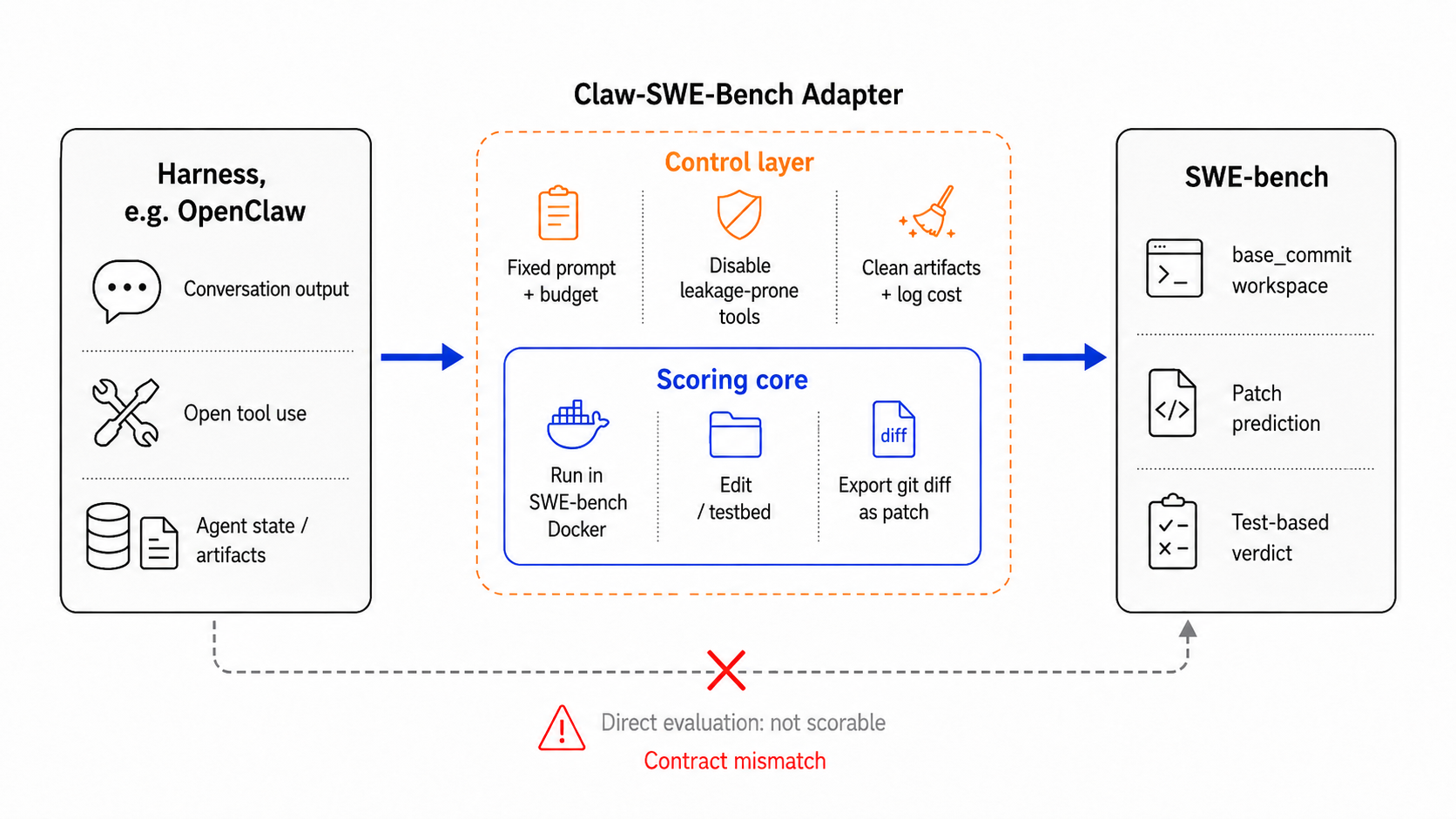
Claw-SWE-Bench 提出标准化适配协议,让不同架构的编码 Agent 能在同一条件下公平对比。对正在选型或自研 Agent 框架的团队,它揭示了「适配器设计」对最终代码生成质量的关键影响,此前被严重低估。
媒体预览
编辑判断
当前编码 Agent 的评测乱象在于各框架自说自话,环境配置、工具调用接口千差万别,导致论文里的数字无法横向比较。Claw-SWE-Bench 的适配器协议本质上是在做「评测层的 Linux 标准」,这跟去年 LMSYS 的 Chatbot Arena 对对话模型的统一评测有相似的战略价值。
论文热度不算高但值得跟踪:如果该协议被 SWE-bench 官方或主流框架采纳,未来 Agent 的 leaderboard 将重新洗牌。目前 HuggingFace 上已有初步代码,建议做 Agent infra 的团队先跑一遍自家框架的适配成本,这比等别人发榜再追更主动。